Findings
Updated May 13, 2019
Vocabulary and Word Use Patterns
Results of Single Word Frequencies
Pearson correlations for word use frequencies compares absolute use frequencies for words found in ALL THREE of the Subject sub-categories (excluding Basic Criteria). Results of one analysis are illustrated below.
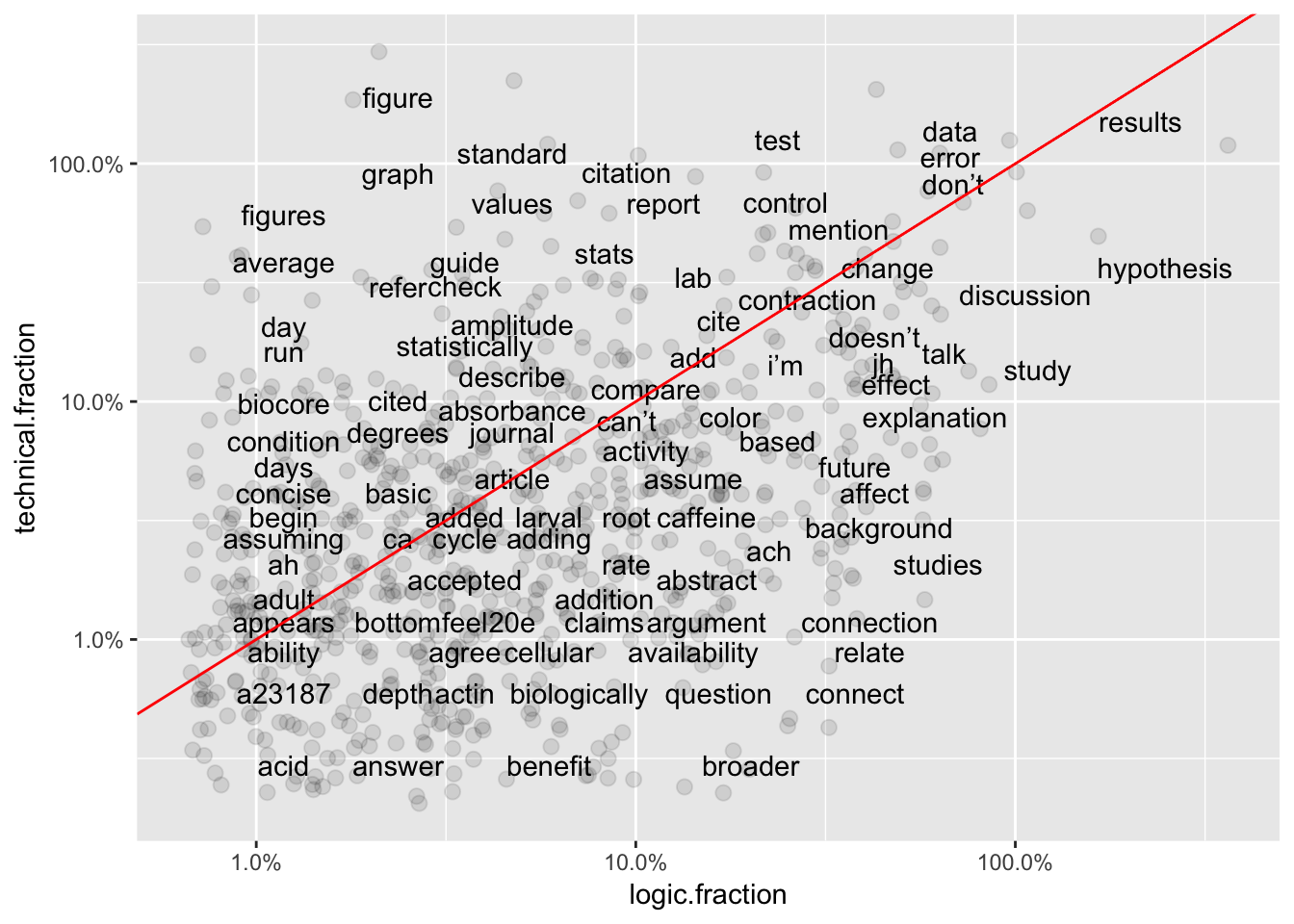
XY plot of relative word use frequency in technical comments vs. logic comments.
Results are summarized below.
| Comparison | Correlation | 95% CI | p-value |
|---|---|---|---|
| Writing vs. Technical | 0.404 | 0.355 - 0.451 | 1.64e-47 |
| Writing vs. Logic | 0.559 | 0.514 - 0.602 | 3.60e-79 |
| Logic vs. Technical | 0.394 | 0.343 - 0.443 | 3.05e-42 |
The comparatively low correlations of word frequencies between subject categories suggests that some terms can serve as diagnostic keywords for particular subjects.
Results of Log-Odds Pairs for Subject Sub-Categories
Word frequency differences between sub-categories were calculated using log-odds ratios. One example analysis is shown below.
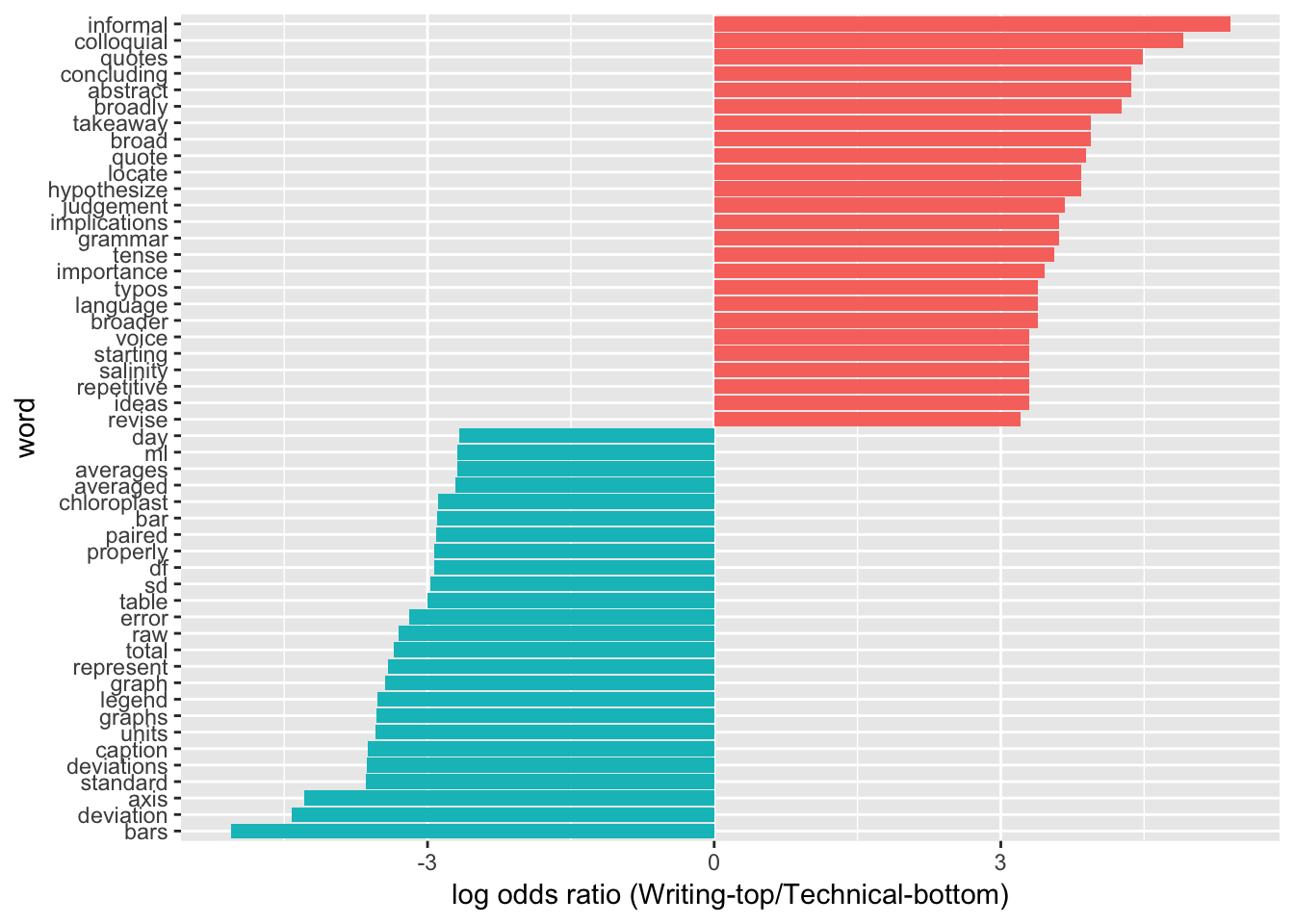
Log-Odds ratio comparison of words most different between Writing comments (top) and Technical comments (bottom).
Words identified by individual analyses were collated into two lists: highly predictive (those appearing in two comparisions) and moderately predictive (those found in one comparison).
Words for Subject = 2. Writing
Highly predictive Broad, broader, broadly; colloquial; language; quote, quotes, quotations; revise; tense
Moderately predictive Abstract; avoid; belongs; concise; concluding; details; formal; grammar; hypothesize; ideas; implications; importance; incorrect; informal; judgement; language; locate; methods; paraphrase; precise; read; recipe; redundant; repetitive; salinity; save; starting; style; takeaway; title; typos; voice; word; wrote
Words for Subject = 3. Technical
Highly predictive Average, averaged, averages; axis; bar, bars; caption, captions; deviation; figure, figures; format, formatting; graph, graphs; legend; paired; raw; represent; sd; standard; table, tables; units
Moderately predictive Chloroplast; day; df; error; label; ml; properly; stat; total
Words for Subject = 4. Logic
Highly predictive Connect, connection; expect, expected; relate; shelter
Moderately predictive Affecting; benefits; biological; broader; build; calculated; chloroplast; concluding; costs; density; dots; error; evolution; expand; explore; finding; fitness; gain; grow; hypothesize; ideas; implications; importance; isolated; logical; mechanisms; prediction; procedural; relative; relevance; resources; salinity; sample; selection; sodium; temp; tie; weren’t
Results of N-Gram Frequency Comparisons
I also tried a limited scale test of an alternative approach, using 2-word phrases (2-grams) instead of single words to classify TA comments. Lists of 2-grams and relative frequencies of appearance were calculated for TA comments in all Subject categories (Basic, Writing, Technical, Logic). N-gram lists were sorted by appearance frequencies, and truncated at a within-subject frequency of <1%, producing a starting dataset of ~550 2-grams.
All 2-grams occurring at similar rates in 3 out of 4 Subject categories were classified as too general and deleted, leaving a working dataset of ~338 2-grams (out of original 550). Remaining 2-grams were tagged as potential identifiers of 1-2 Subject areas. The individual 2-gram lists were merged back to the master set and sorted alphabetically.
The compiled set was visually scanned to identify individual 2-grams and 2-gram patterns that:
- Appeared in at least 1% of all comments in one sub-group
- Appeared at a 10-fold greater frequency in one sub-group versus all others.
Full analysis of the dataset requires writing a coded search algorithm; for now, I am treating these results as s “proof-of-concept” demonstration only.
This is a partial list of the potentially useful 2-grams identified so far.
- Subject = Basic
- “basic criteria/criterion” (present in 25.12% of all Basic comments)
- “missing outside”" (6.64% of all Basic comments)
- “outside source(s)”" (13.75% of all Basic comments)
- “criteria __"
- Single words (1-grams) strongly correlated with Basic category: basic, credit, grade, criteria, fail/failing, outside
- Subject = Writing
- “abstract __"
- “avoid __"
- “capitalize __"
- “colloquial __"
- Subject = Technical
- amplitude
- analysis/analyze
- “a figure/graph/legend”
- “a paired”
- alpha level/value"
- “annotation exercise”
- “anova __"
- “average __"
- “bar(s) __"
- “caption(s) __"
- Subject = Logic
- “a biological”
- “affect __"
- “aggression/aggressive __"
- “allocation __"
- “axis __"
- “betta(s) __" (Is name of model system typically logic?)
- big(ger) picture/concept is logic
- connect “__"
- N-grams Identifying TWO Subjects
- “a citation” is basic or technical
- “a significant” is logic or technical
- “about __" is logic, possibly writing. Weaker example.
- “background __" is writing or logic
- “because that’s” is writing/technical
- “(bio)core guide/resource” is technical or writing
- “biological __" is logic or writing
- “broader __" is logic or writing
- “data __" is most often technical, but occurs in others.
Classifier Accuracy
The tables below show observed frequencies for 9,340 TA comments coded by hand, and frequencies for the same TA comments categorized using the optimized Naive Bayes classifier without pre-screening. The far right columns are overall subject frequencies, the bottom rows, overall structure frequencies.
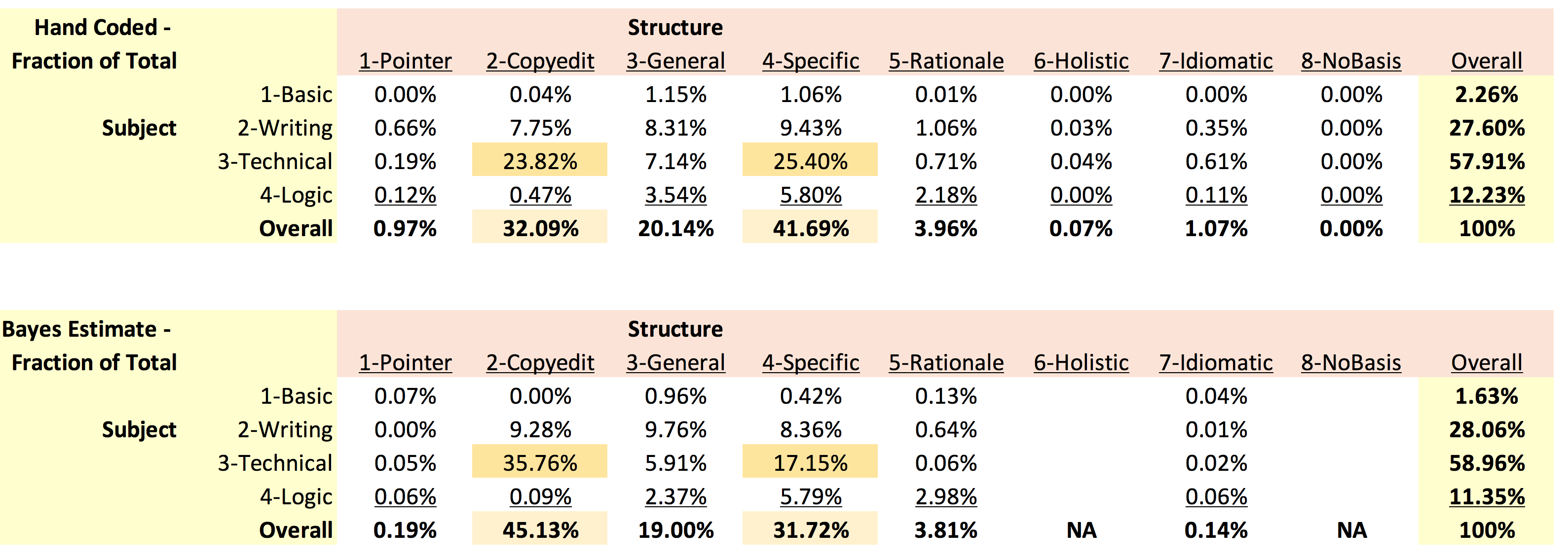
Comparison of frequency tables generated by hand-coding TA comments (top) versus predicted categories using optimized NB classifier (bottom).
On average, the classifier is only 80-90% accurate for one subject sub-category or one specific comment. OVERALL though, the optimized NB classifier estimated relative frequencies of Subject subcategories very well; there was <1.5% difference in fractional frequencies between observed (hand-coded) and computationally assigned Subject sub-categories.
Overall accuracy was considerably lower for Structure sub-categories. Specifically, the NB classifier over-assigned comments to the “Copy-editing” sub-category, and under-assigned comments to the “Specifics” sub-category. Most incorrectly classified comments belonged to the “Technical” Subject sub-category. This suggest there may be specific terms present in comments within this sub-category that are problematic, and warrant further exploration.
Test of Horizontal Stacked Naive Bayes
One strategy to refine Naive Bayes was running the same classifier with different randomized datasets, then putting individual outputs side by side and assigning final categories based on most frequent classification in the set.
To test this I ran 5 Subject classifier replicates using the code in Naive_bayes_V2r_2b.rmd, with 5 different set.seed values. The exported CSV files were combined to get a set of data with up to 5 classifier assignments for the same comment.
Using multiple randomized NB training runs does not seem to help. First, it was rare for the randomized runs to assign different incorrect classes. Second, when I compared 5 independently randomized runs by eye, incorrectly categorized items were repeatedly put into the SAME incorrect group each time. Given this, an Ensemble method of H-stacked categorical NB comparison seems unlikely to reduce overall errors in classification.
Looking at the joined data DID provide other helpful insights into the overall classification procedure though. Naive Bayes does not seem to do well with comments that:
- Contain many or mostly punctuation symbols, such as:
- : not ,
- ?
- ??
- ???
- Are whole numbers
- 1
- 2
- 10
- Are one word questions or comments
- because?
- “and”
- Are sentences enclosed in punctuation
- Are made up entirely of STOP/common words (I am not as sure on this one)
Overall Accuracy
I looked at OVERALL accuracy of NB by recreating the 2-dimensional contingency table that I made when hand-coding, and comparing it side-by-side to NB classifications. From this I gained additional insights. Results are summarized below.
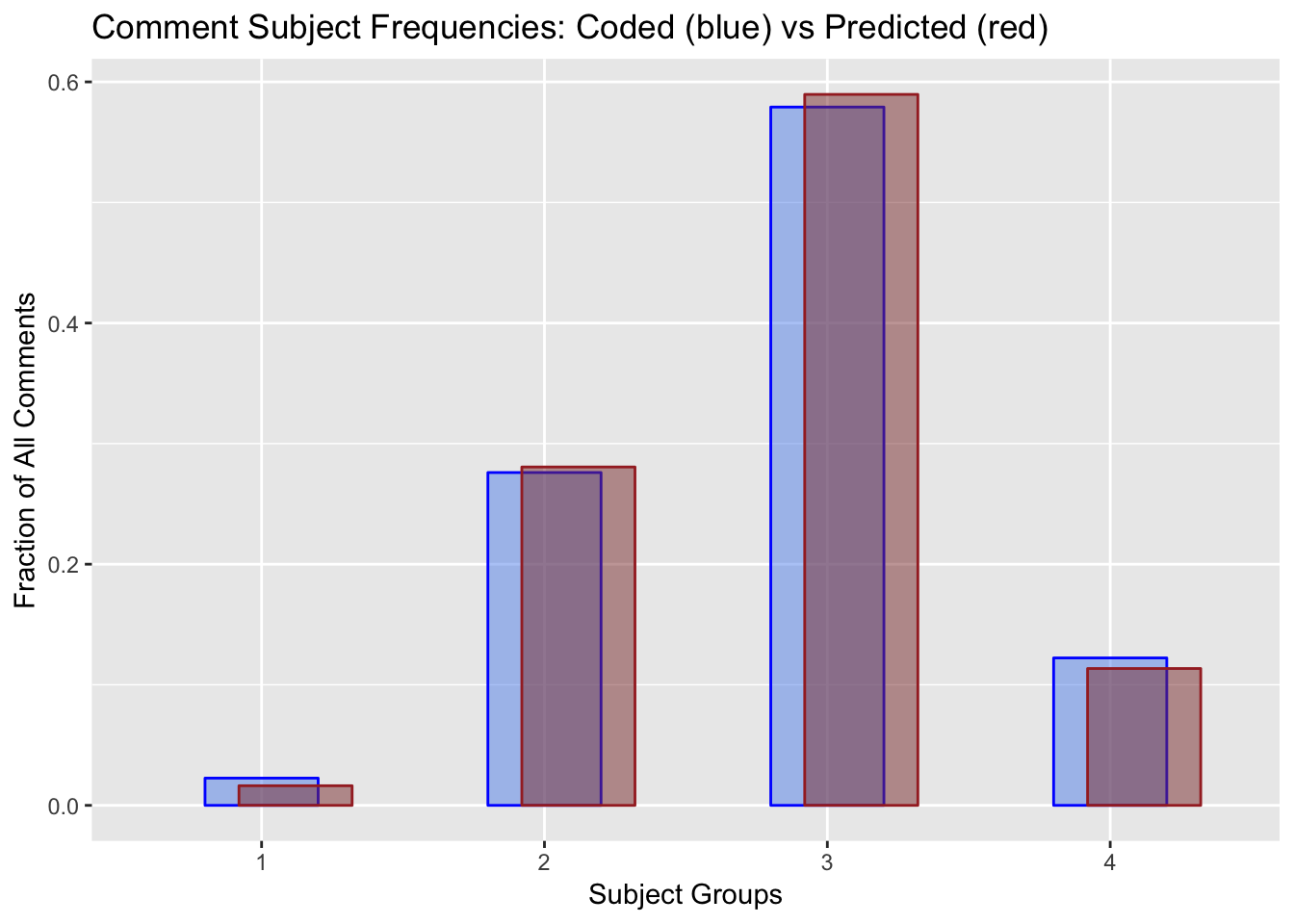
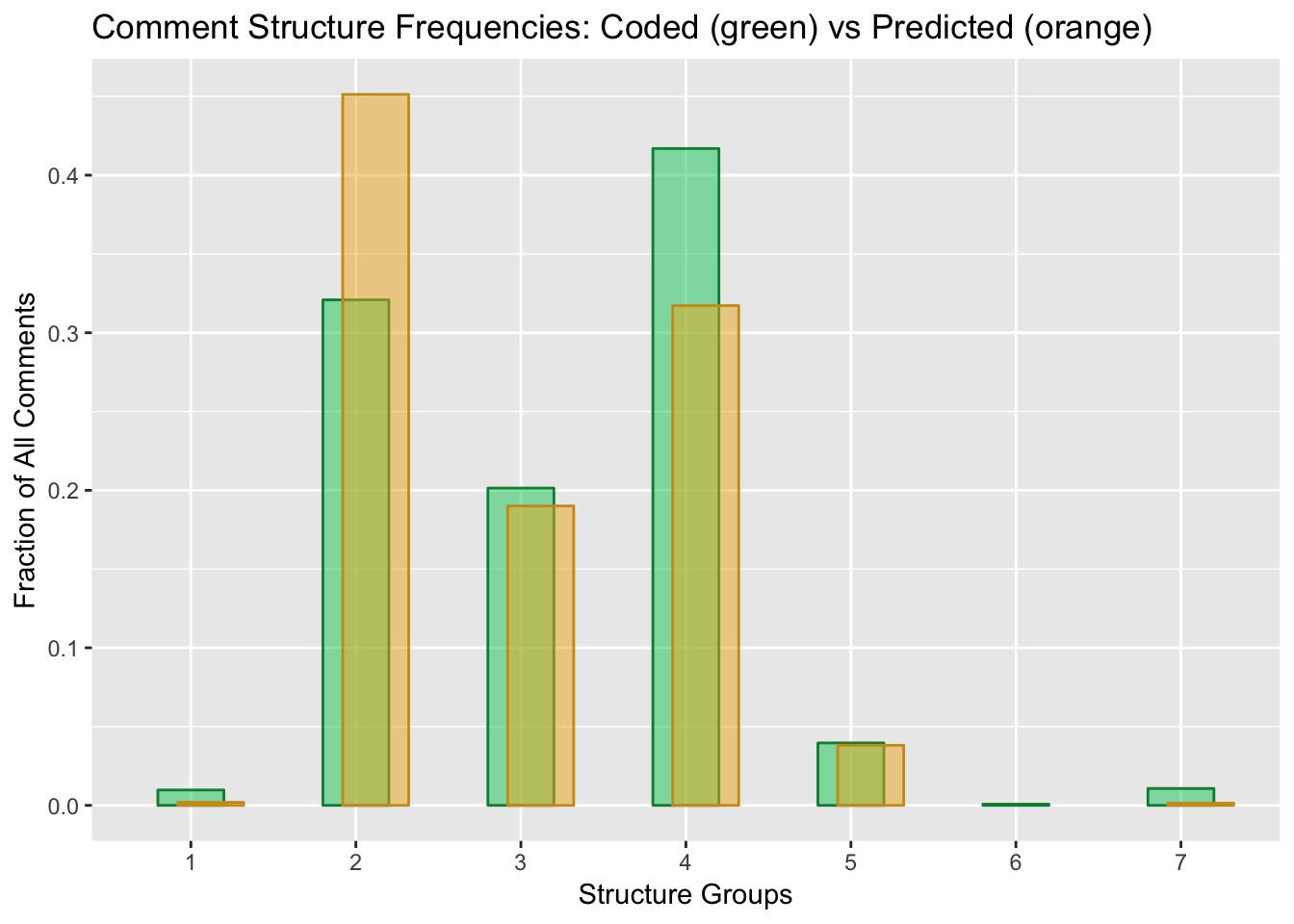
OVERALL, the 2-D Naive Bayes model performed very well for classifying comment Subject. When I re-ran the full original dataset (9340 comments) through the prediction model, NB estimates for Subject were within 1.5% of my hand-scored assignments. Structure classification was not as robust. Other observations:
- NB over-classified comments as “copyediting of technical issues” by 8-10%, and under-classified comments that should be marked as “specific technical issues” by almost same amount.
- Comments that belonged to groups comprising <1-2% of all comments were more likely to be mis-classified.
- Longer text comments were mis-classified more often. This suggests two follow-up methods to evaluate:
- Splitting longer comments into shorter phrases
- Evaluating only the first 5-10 words of a comment
It appears that Subject categories are assigned mainly on the terminology used, while Structure categories are assigned based more on the sentiment and sentence structure of a comment. This suggests that a sentiment classifier or PoS tagger step needs to be added.
Looking Ahead
Mixed Ensemble Method
Based on the results outlined above, it appears that maximum classification accuracy will be a mixed vertical Ensemble method. Going forward, the working strategy will be to:
- Pre-screen extracted TA feedback for “short-string” comments consisting of single words, two-word phrases, more punctuation than text, etc. These represent mostly pointers and copy-editing.
- Screen comments for 2-grams with high frequencies in one particular category. (Ex., “basic criteria” 2-gram.)
- Use current Naive Bayes classifier to identify Subject.
- Evaluate whether a part-of-speech tagger can identify Structure of comments with higher accuracy, either alone when joined with NB preliminary classification.
Copyright © 2019 A. Daniel Johnson. All rights reserved.